 Toward General Instruction-Following Alignment for Retrieval-Augmented Generation
Toward General Instruction-Following Alignment for Retrieval-Augmented Generation
Following natural instructions is crucial for the effective application of Retrieval-Augmented Generation (RAG) systems. Despite recent advancements in Large Language Models (LLMs), research on assessing and improving instruction-following (IF) alignment within the RAG domain remains limited.
To address this issue, we propose VIF-RAG, the first automated, scalable, and verifiable synthetic pipeline for instruction-following alignment in RAG systems. We start by manually crafting a minimal set of atomic instructions (<100) and developing combination rules to synthesize and verify complex instructions for a seed set. We then use supervised models for instruction rewriting while simultaneously generating code to automate the verification of instruction quality via a Python executor. Finally, we integrate these instructions with extensive RAG and general data samples, scaling up to a high-quality VIF-RAG-QA dataset (>100k) through automated processes.
To address the gap in instruction-following auto-evaluation for RAG systems, we introduce FollowRAG Benchmark, which includes approximately 3K test samples, covering 22 categories of general instruction constraints and 4 knowledge-intensive QA datasets. Due to its robust pipeline design, FollowRAG can seamlessly integrate with different RAG benchmarks.
Using FollowRAG and 8 widely-used IF and foundational abilities benchmarks for LLMs, we demonstrate that VIF-RAG markedly enhances LLM performance across a broad range of general instruction constraints while effectively leveraging its capabilities in RAG scenarios. Further analysis offers practical insights for achieving IF alignment in RAG systems.
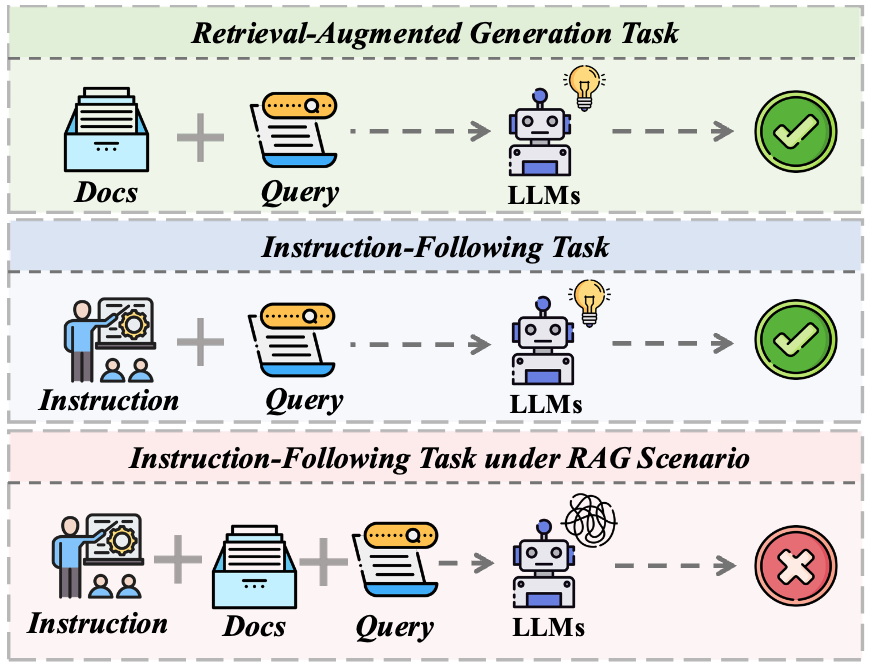
An example of instruction-following tasks for LLMs in RAG scenarios..

The Performance Comparison between Mistral-7B base and SFT version models on Different Tasks.
It is the first automated, scalable, and verifiable data synthesis pipeline for aligning complex instruction-following in RAG scenarios. VIF-RAG integrates a verification process at each step of data augmentation and combination. We begin by manually creating a minimal set of atomic instructions (<100) and then apply steps including instruction composition, quality verification, instruction-query combination, and dual-stage verification to generate a large-scale, high-quality VIF-RAG-QA dataset (>100K).
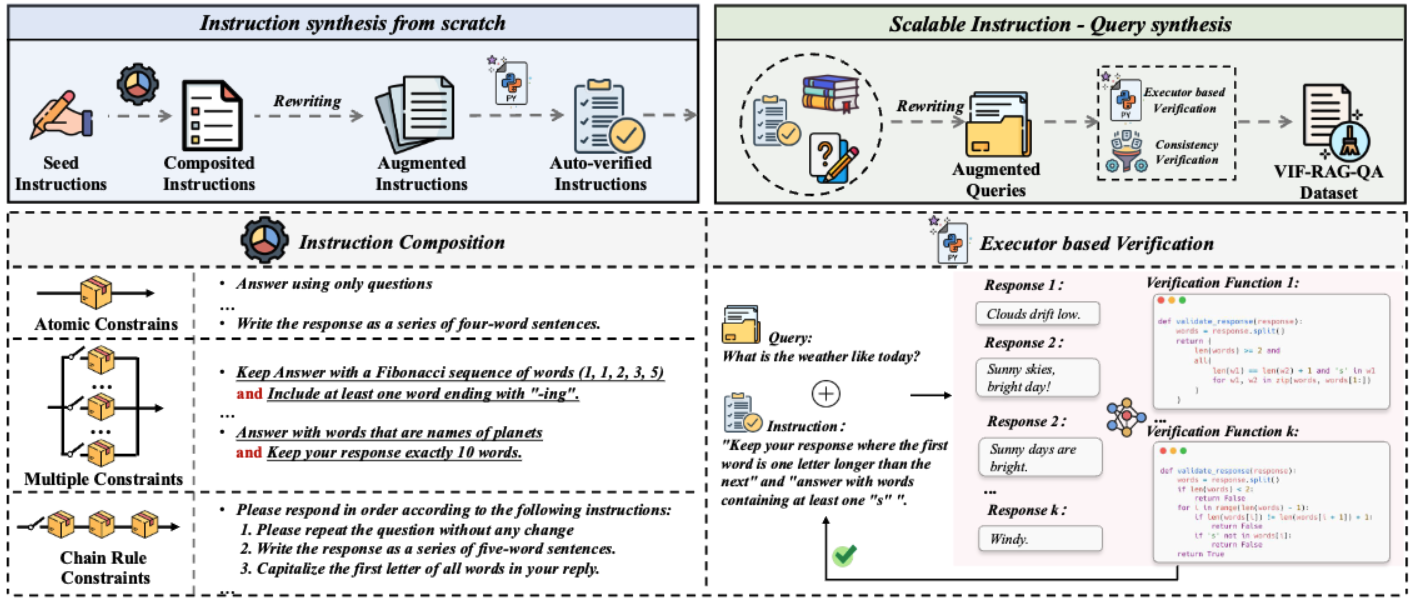
The Overall Framework of VIF-RAG.

The Instruction Composition of VIF-RAG.
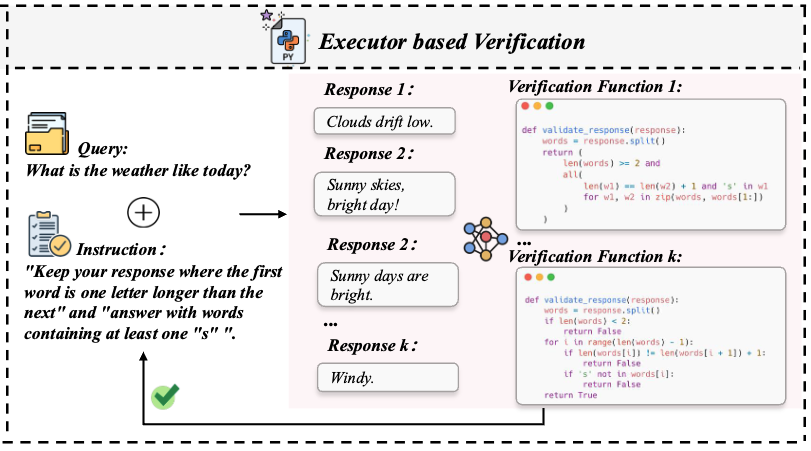
The Executor based verification of VIF-RAG.
To address the gap in instruction-following auto-evaluation for RAG systems, we introduce FollowRAG Benchmark, which includes approximately 3K test samples, covering 22 categories of general instruction constraints and 4 knowledge-intensive QA datasets. Due to its robust pipeline design, FollowRAG can seamlessly integrate with different RAG benchmarks
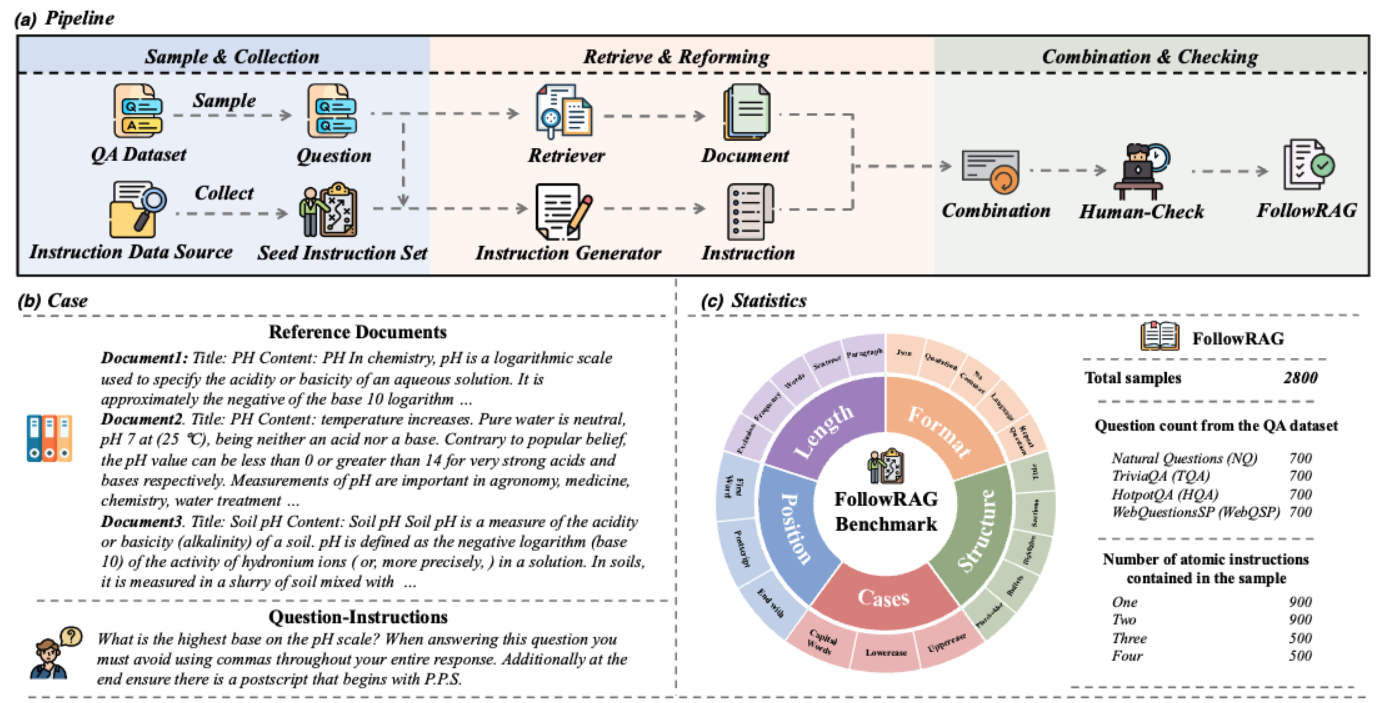
The construction pipeline, diagram and statistics of VIF-RAG.
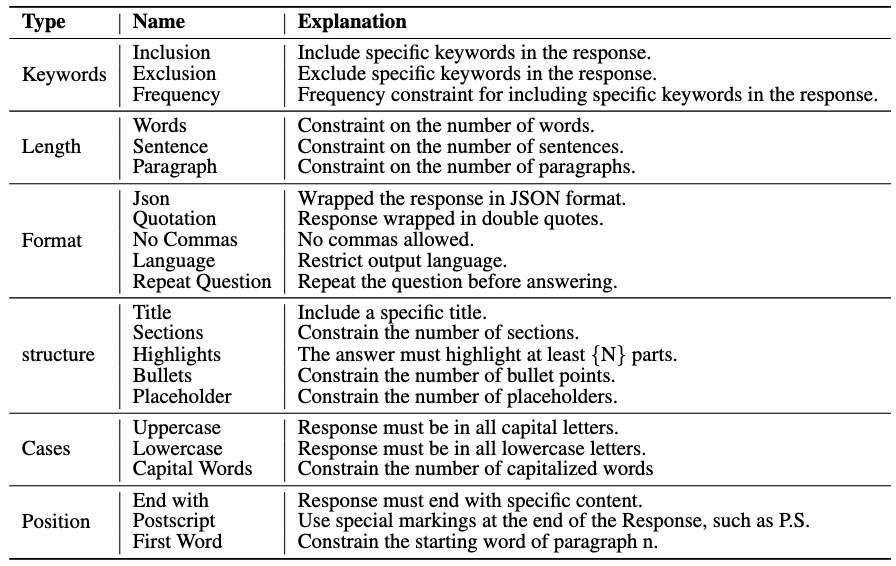
The construction pipeline of VIF-RAG.
The construction pipeline of VIF-RAG.

The case of VIF-RAG.
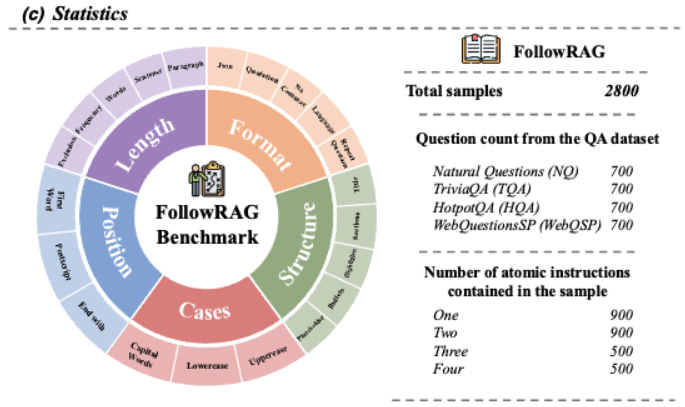
The statistics of VIF-RAG.
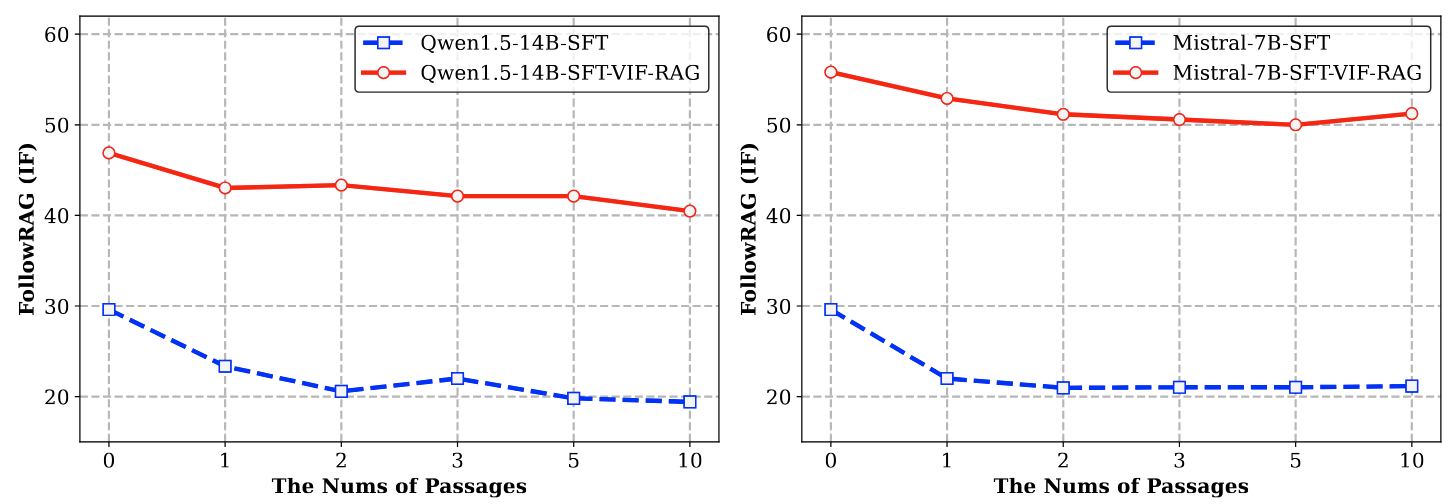
The scaling analysis of document count and FollowRAG (IF) performance..
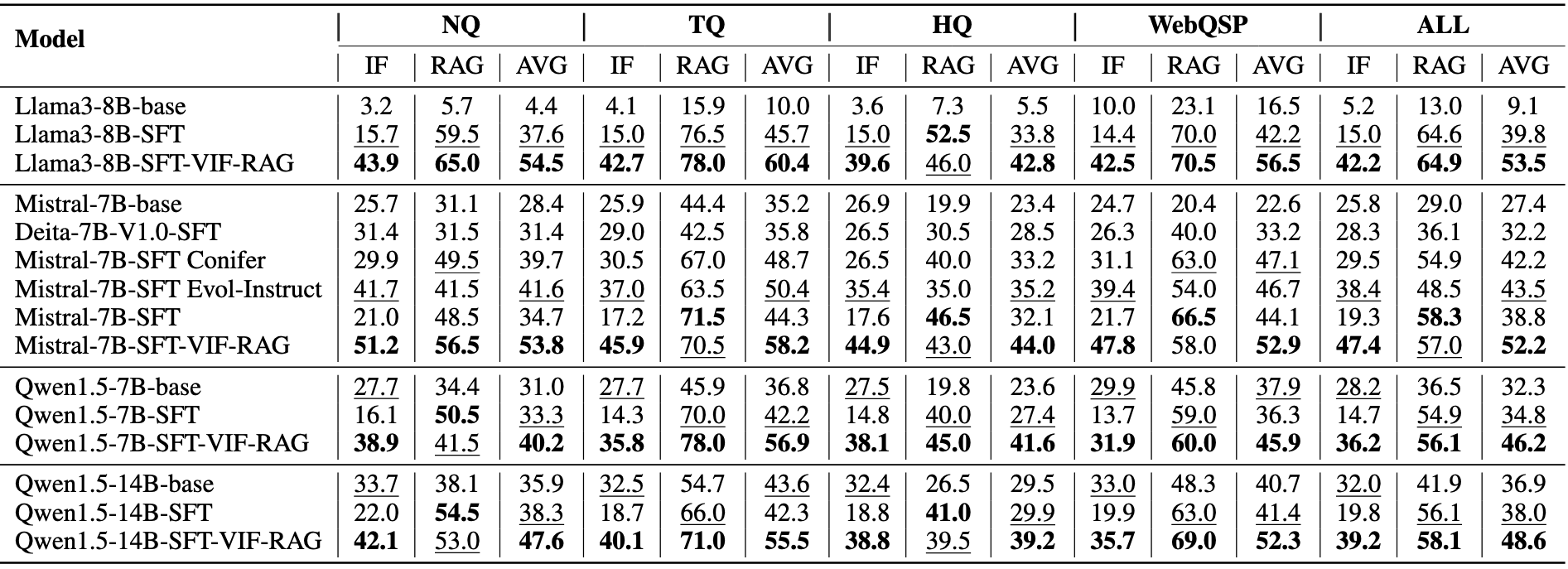
The main results on FollowRAG.“AVG” represents the weighted average of the corresponding IF and RAG scores. The best two results for each column are bolded and underlined.
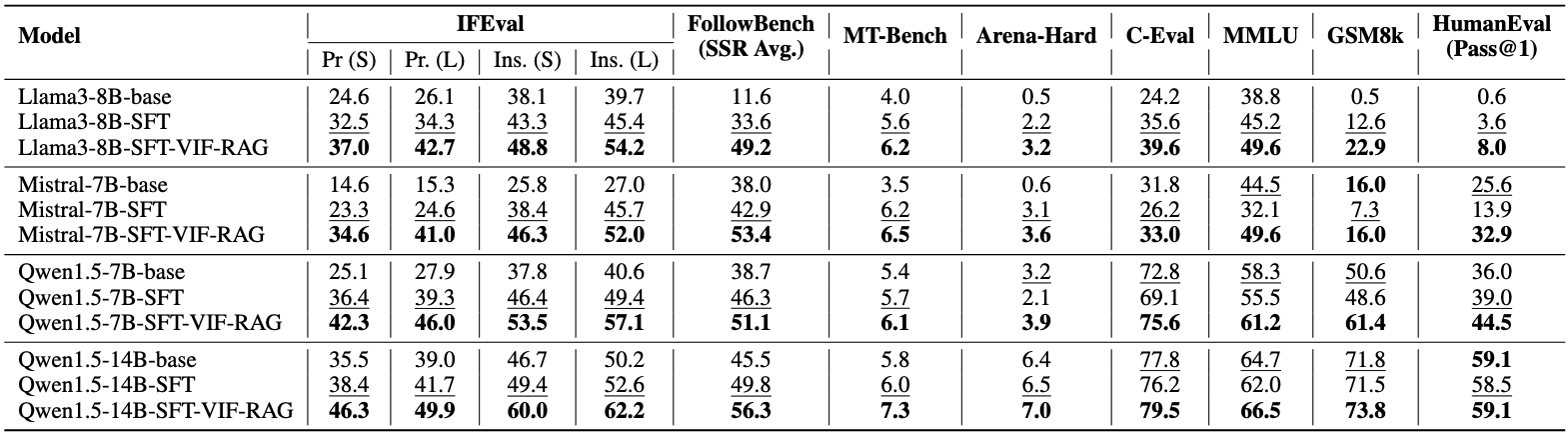
The cross-domain validation on 4 general instruction-following (Left 4) and 4 foundational abilities (Right 4) bench- marks. Pr. and Ins. stand for prompt and instruction levels, respectively. S and L represent strict and loose metrics for IFEval.
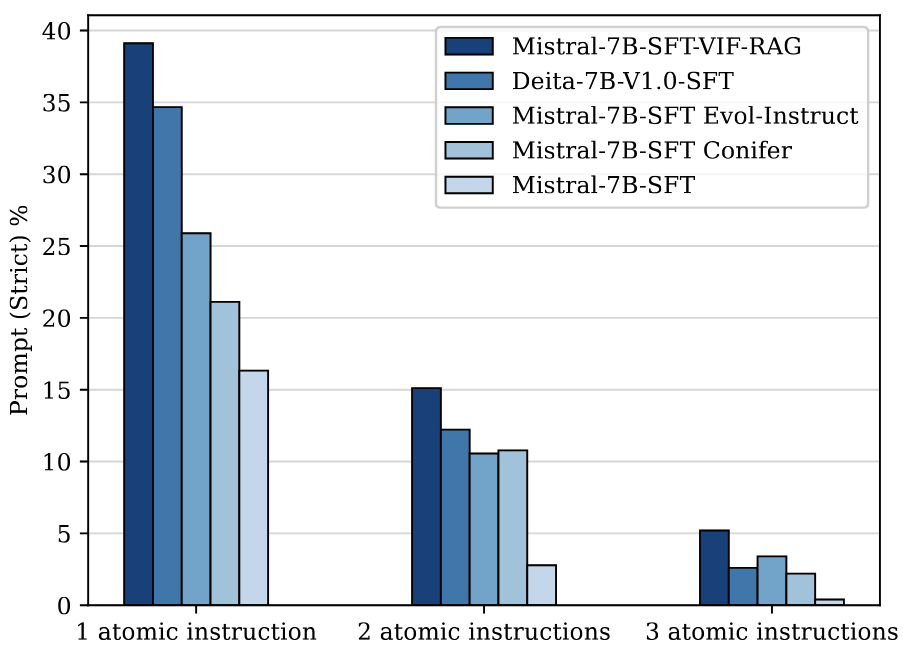
The analysis of instruction counts on FollowRAG (IF) performance.

A case study (1) of VIF-RAG and different models in the followrag benchmark, with the backbone Mistral-7B. .
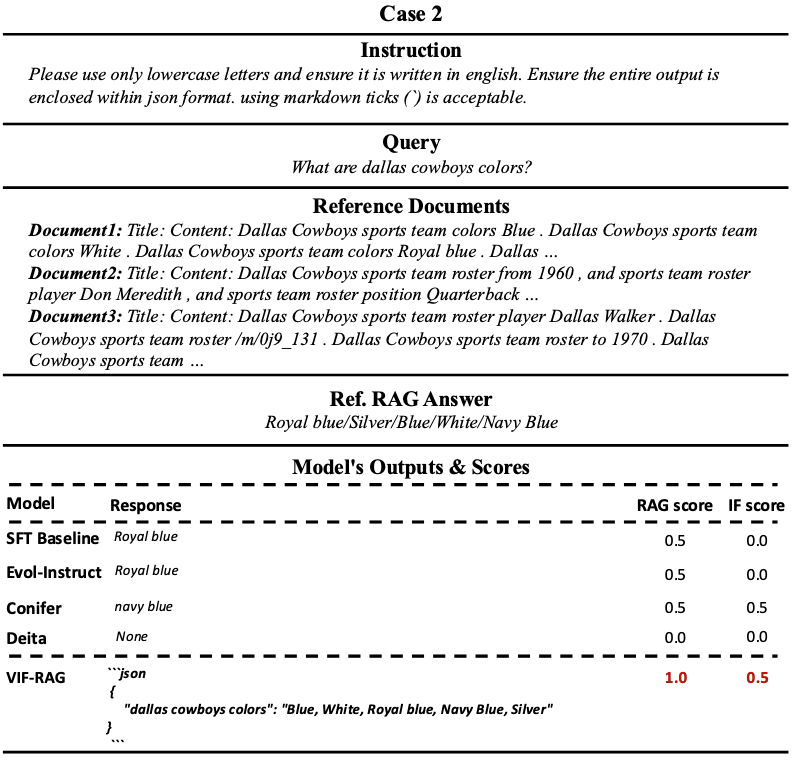
A case study (2) of VIF-RAG and different models in the followrag benchmark, with the backbone Mistral-7B. .

A case study (3) of VIF-RAG and different models in the followrag benchmark, with the backbone Mistral-7B. .
@article{dong2024general,
author = {Guanting Dong and
Xiaoshuai Song and
Yutao Zhu and
Runqi Qiao and
Zhicheng Dou and
Ji{-}Rong Wen},
title = {Toward General Instruction-Following Alignment for Retrieval-Augmented
Generation},
journal = {CoRR},
volume = {abs/2410.09584},
year = {2024},
url = {https://doi.org/10.48550/arXiv.2410.09584},
doi = {10.48550/ARXIV.2410.09584},
eprinttype = {arXiv},
eprint = {2410.09584},
timestamp = {Fri, 22 Nov 2024 21:38:25 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2410-09584.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
